 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECEIVE-AFC: Adversarial Claim Attacks against Search-Enabled LLM-based Fact-Checking Systems
Jan 31, 2026Fact-checking systems with search-enabled large language models (LLMs) have shown strong potential for verifying claims by dynamically retrieving external evidence. However, the robustness of such systems against adversarial attack remains insufficiently understood. In this work, we study adversarial claim attacks against search-enabled LLM-based fact-checking systems under a realistic input-only threat model. We propose DECEIVE-AFC, an agent-based adversarial attack framework that integrates novel claim-level attack strategies and adversarial claim validity evaluation principles. DECEIVE-AFC systematically explores adversarial attack trajectories that disrupt search behavior, evidence retrieval, and LLM-based reasoning without relying on access to evidence sources or model internals. Extensive evaluations on benchmark datasets and real-world systems demonstrate that our attacks substantially degrade verification performance, reducing accuracy from 78.7% to 53.7%, and significantly outperform existing claim-based attack baselines with strong cross-system transferability.
On the Adversarial Robustness of Large Vision-Language Models under Visual Token Compression
Jan 29, 2026Visual token compression is widely used to accelerate large vision-language models (LVLMs) by pruning or merging visual tokens, yet its adversarial robustness remains unexplored. We show that existing encoder-based attacks can substantially overestimate the robustness of compressed LVLMs, due to an optimization-inference mismatch: perturbations are optimized on the full-token representation, while inference is performed through a token-compression bottleneck. To address this gap, we propose the Compression-AliGnEd attack (CAGE), which aligns perturbation optimization with compression inference without assuming access to the deployed compression mechanism or its token budget. CAGE combines (i) expected feature disruption, which concentrates distortion on tokens likely to survive across plausible budgets, and (ii) rank distortion alignment, which actively aligns token distortions with rank scores to promote the retention of highly distorted evidence. Across diverse representative plug-and-play compression mechanisms and datasets, our results show that CAGE consistently achieves lower robust accuracy than the baseline. This work highlights that robustness assessments ignoring compression can be overly optimistic, calling for compression-aware security evaluation and defenses for efficient LVLMs.
Physical Prompt Injection Attacks on Large Vision-Language Models
Jan 24, 2026Large Vision-Language Models (LVLMs) are increasingly deployed in real-world intelligent systems for perception and reasoning in open physical environments. While LVLMs are known to be vulnerable to prompt injection attacks, existing methods either require access to input channels or depend on knowledge of user queries, assumptions that rarely hold in practical deployments. We propose the first Physical Prompt Injection Attack (PPIA), a black-box, query-agnostic attack that embeds malicious typographic instructions into physical objects perceivable by the LVLM. PPIA requires no access to the model, its inputs, or internal pipeline, and operates solely through visual observation. It combines offline selection of highly recognizable and semantically effective visual prompts with strategic environment-aware placement guided by spatiotemporal attention, ensuring that the injected prompts are both perceivable and influential on model behavior. We evaluate PPIA across 10 state-of-the-art LVLMs in both simulated and real-world settings on tasks including visual question answering, planning, and navigation, PPIA achieves attack success rates up to 98%, with strong robustness under varying physical conditions such as distance, viewpoint, and illumination. Our code is publicly available at https://github.com/2023cghacker/Physical-Prompt-Injection-Attack.
TransTroj: Transferable Backdoor Attacks to Pre-trained Models via Embedding Indistinguishability
Jan 29, 2024Pre-trained models (PTMs) are extensively utilized in various downstream tasks. Adopting untrusted PTMs may suffer from backdoor attacks, where the adversary can compromise the downstream models by injecting backdoors into the PTM. However, existing backdoor attacks to PTMs can only achieve partially task-agnostic and the embedded backdoors are easily erased during the fine-tuning process. In this paper, we propose a novel transferable backdoor attack, TransTroj, to simultaneously meet functionality-preserving, durable, and task-agnostic. In particular, we first formalize transferable backdoor attacks as the indistinguishability problem between poisoned and clean samples in the embedding space. We decompose the embedding indistinguishability into pre- and post-indistinguishability, representing the similarity of the poisoned and reference embeddings before and after the attack. Then, we propose a two-stage optimization that separately optimizes triggers and victim PTMs to achieve embedding indistinguishability. We evaluate TransTroj on four PTMs and six downstream tasks. Experimental results show that TransTroj significantly outperforms SOTA task-agnostic backdoor attacks (18%$\sim$99%, 68% on average) and exhibits superior performance under various system settings. The code is available at https://github.com/haowang-cqu/TransTroj .
Local Black-box Adversarial Attacks: A Query Efficient Approach
Jan 04, 2021

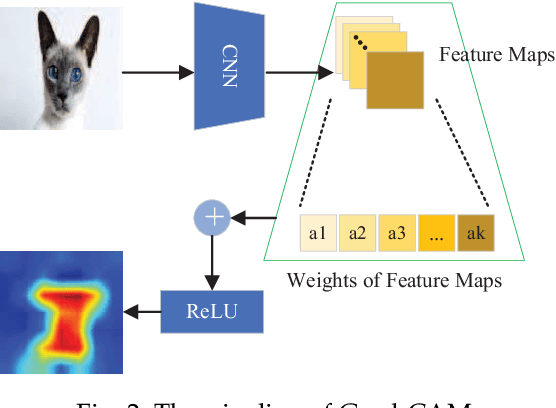

Adversarial attacks have threatened the application of deep neural networks in security-sensitive scenarios. Most existing black-box attacks fool the target model by interacting with it many times and producing global perturbations. However, global perturbations change the smooth and insignificant background, which not only makes the perturbation more easily be perceived but also increases the query overhead. In this paper, we propose a novel framework to perturb the discriminative areas of clean examples only within limited queries in black-box attacks. Our framework is constructed based on two types of transferability. The first one is the transferability of model interpretations. Based on this property, we identify the discriminative areas of a given clean example easily for local perturbations. The second is the transferability of adversarial examples. It helps us to produce a local pre-perturbation for improving query efficiency. After identifying the discriminative areas and pre-perturbing, we generate the final adversarial examples from the pre-perturbed example by querying the targeted model with two kinds of black-box attack techniques, i.e., gradient estimation and random search. We conduct extensive experiments to show that our framework can significantly improve the query efficiency during black-box perturbing with a high attack success rate. Experimental results show that our attacks outperform state-of-the-art black-box attacks under various system settings.